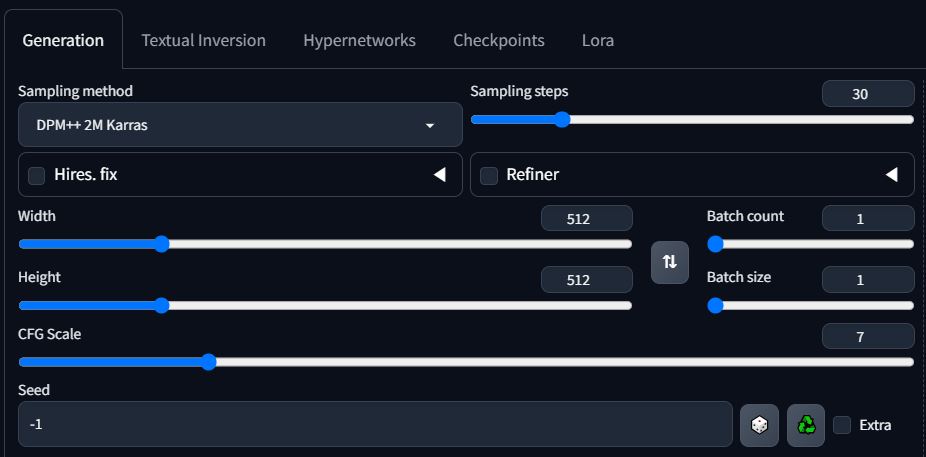
지금 까지 스테이블 디퓨전 AI 이미지 생성 방식에 대해서 알아보았습니다. 이번에는 결과물을 생성해 보도록 하겠습니다. 많은 사람들이 AI 이미지 하면 떠올리시는 AI 이미지를 생성하기 위해서는 Checkpoint부터 시작해서 여러 가지 준비가 필요합니다. 이번에 사용된 Checkpoint는 Civitai에서 검색해서 무료로 받으실 수 있는 XXMix_9realistic 체크 포인트입니다. 그 외의 추가 Extension은 사용하지 않는 상태로 생성해 보도록 하겠습니다.
XXMix_9realistic 사용
XXmix_9realistic checkpoint는 Civitai에서도 높은 추천수를 받고 있는 Checkpoint입니다.
지속적인 업데이트가 진행 중인 프로젝트이고 인터넷에서 보통 보시는 AI generated image들의 얼굴을 다수 포함 하고 있습니다.
만약 AI 이미지 생성에 관심 가진 이유 중 하나가 평상시 인터넷에서 보시던 이미지를 한번 생성해보고 싶어서 시작하셨다면 최적의 체크 포인트가 될 것 같습니다.
이미지는 클릭하시면 확대해서 보실 수 있습니다.
 |
 |
 |
 |
사용된 Prompt입니다.
1. Prompt - (a girl standing in Nature), masterpiece, best quality, (1 girl), 8k, very detailed, high detailed texture, cinematic illumination, volumetric lighting, black hair, elegant makeup
2. Negative Prompt - (nsfw:1.1), easy negative,ng_deepnegative_v1_75t,(worst quality:1.5),(low quality:1.5),(normal quality:2),low-res, bad anatomy, bad hands, normal quality,((watermark)), mark)), blurry, logo, disfigured face, morbid,
이미지 생성 가이드
1. 위의 이미지들은 전부 512 X 512 사이즈로 제작되어 얼굴이 중심이 된 이미지로 생성되었습니다.
만약 전체 샷을 원하는 경우 1024 X 1024 사이즈로 제작하시면 다른 프롬프트를 건들지 않고 생성 가능 합니다.
https://civitai.com/models/47274/xxmix9realistic 에서 Checkpoint는 다운로드하실 수 있습니다.
결론
현제 대부분의 AI 생성 이미지는 위의 얼굴로 제작되는 것을 보실 수 있습니다.
이는 AI 생성 과정에서 대칭 형 얼굴 중 보편적으로 인간이 아름답다고 생각되는 얼굴 형이 위의 얼굴입니다.
위의 얼굴에서 벗어나서 다른 얼굴 형으로 AI 이미지를 생성하시고 싶으시면 얼굴에 관한 프롬프트를 추가 입력 하시면 됩니다.
또는 얼굴 변경을 위하여 LORA를 추가하는 방법도 있습니다
그 이외에 방법으로는 다른 얼굴 형을 학습된 Checkpoint를 찾아 생성하는 방법도 있습니다.
'Stable diffusion' 카테고리의 다른 글
| Stable Diffusion Sampling method (0) | 2024.04.11 |
|---|---|
| Stable Diffusion Sampling Steps Guide (0) | 2024.04.09 |
| Stable Diffusion CFG Scale Guide (0) | 2024.04.06 |
| Stable Diffusion WebUI 설정 옵션 저장 하는 방법 (2) | 2024.04.05 |
| Stable diffusion prompt 알아내기 (2) | 2024.04.04 |